Your PWA is still a webpage that customers can find in their usual ways. You want to apply reasonable search engine optimization and ensure the page is available to search engines. You can use JavaScript on your pages and Google will index it as long as you follow some best practices. You can use the fetch as Google tool from the Google webmasters site to see how your app looks when crawled discoverability helps get customers to your site.
But how can you measure their behaviors once they get there? That’s where analytics comes in Google Analytics is a service that collects processes and reports, data about an applications, use patterns and performance. Adding Google Analytics to a web application enables the collection of data like visitor traffic, user agent, the user’s location, etc. This data is sent to Google Analytics servers where it’s processed.
The reports are available in the Google Analytics web interface and through a reporting API, Google Analytics is free and highly customisable. Integrating Google Analytics is simple. First, you must create a Google Analytics account. Each account has properties, and these aren’t JavaScript properties, but refer to individual applications or websites. Google Analytics then generates a tracking snippet for each property.
This is a piece of JavaScript that you pasted into your page. It sends data to the Google Analytics back-end. You can also use the analytics library to create custom analytics, such as tracking specific user actions or tracking push notifications. I want to say a bit more about properties. An account has properties that represent individual collections of data. These properties have property, IDs, also called tracking IDs.
That identify them to Google Analytics if an account represents a company. One property in that account might represent the company’s website, while another property might represent the company’s mobile application. If you only have one app, the simplest scenario is to create a single Google Analytics, account and add a single property to that account. This is the key part of the tracking snippet.
The entire snippet needs to be pasted into every page. You want to track at a high level when this script runs. It creates an async script tag that downloads analytics AS the analytics library it defines the GA function called the command queue. It creates a tracker that gathers user data and it sends this data as a pageview hit via HTTP request to Google Analytics. This data is analyzed in stored in your analytics account.
In addition to the data gathered by tracker creation, the page view event allows Google Analytics to infer what pages the user is visiting, how long they are visiting them and in what order for simpler applications. This is the only coding required note. You can replace analytics GS with analytics underscore debug KS for console debugging. Using this version will log detailed messages to the console for each hit, sent it also logs warnings and errors for your tracking code.
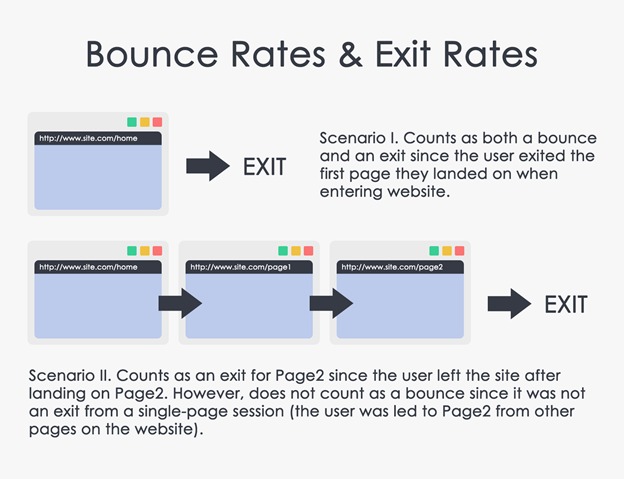
The data is sent to Google Analytics backend where it is processed into reports. These reports are available through the Google Analytics dashboard. Here is the audience overview interface. Here you can see general information such as page view, records bounce rate, ratio of new and returning visitors and other statistics. You can also see specific information like a visitor’s language, country, city, browser operating system, service provider, screen resolution and device.
Here we are looking at the user City, it’s also possible to view the analytics information in real time. This interface allows you to see hits as they occur on your site. I encourage you to take some time and explore there’s an extensive set of features in the dashboard. You should explore the standard reports and look at creating your own. Knowing how to use analytics for improving your business or increasing revenue is a skill within itself.
Fortunately, the Google Analytics Academy offers a free set of online courses. Google Analytics supports custom events that allow fine, grained analysis of user behavior. This code uses the G a command Q, which is defined in the tracking snippet. The send command is used to send an analytics event. Values associated with the event are as parameters. These values represent the event, category event, action and event label.
All of these are arbitrary and used to organize events. These custom events allow us to deeply understand user interactions with our site. For example, here we are sending a view more event. This might be used to indicate that the user has viewed an item from our site. The event label tells us that it was a premium product. I mentioned earlier that you might use events to track push notifications.
You can add events to fire when users subscribe or unsubscribe to push notifications as well as when there is an error in a subscription process. This can give you an understanding of how many users are subscribing or unsubscribing to your app here. We send a subscribe event, letting us know that a user has subscribed to our notifications. Let’s talk about what happens when analytics meets service workers, they won’t work without a little help.
That’s because the service worker script runs on its own thread and doesn’t have access to the GA command queue object established by the tracking snippet code on the main thread. It also requires the window object. Service workers must use the measurement protocol API instead of the command Q. This is a simple set of HTTP parameters documented at the Google Analytics site. Here’s an example of recording when the user closes a push notification.
The service worker manages the notification lifecycle, so it receives a notification close event when the event fires, the service worker, sends a hit via post with tracking ID custom event parameters and the required parameters for the API. Remember that we don’t want this service worker to shut down before we complete the post, so we wrap this code in event. Wait until since hits are effectively HTTP requests, they can’t be sent if the user is offline using service worker and indexeddb hits can be stored when users are offline and sent it a later time when they have reconnected.
Fortunately, the SW offline, google analytics and PM package abstracts this process for us to integrate offline analytics, install the package in your project with the npm install command. Then, in the service worker script import, the offline, google analytics import, je and initialize. The google and google analytics object. This adds a fetch event handler to the serviceworker that only listens for requests made to the Google Analytics domain.
The handler attempts to send Google Analytics normally if the network request fails, it will be stored in indexdb. Instead, the stored hits will be resent when online. You can test this behavior by enabling offline mode in developer tools and then triggering Google Analytics hits on your app indexdb will show a list of urls that represent the unsent hit requests. You may need to click the Refresh icon inside the indexdb interface to see them.
If you disable offline mode and refresh the page, you should see that the urls are cleared indicating that they have been sent now. It’s your turn. Go to the analytics API lab in there. You will create an account, add analytics to an app look at the results and make this work in a progressive web, app good luck and have fun if you’re an instructor. This final slide links to more information on analytics.
If you’re a student, these links can be found in your textbook. You may want to use these while you are working on the lab. There are additional slides at the end of this presentation that show the major analytic screens and explain how to get there, use these to deepen your knowledge or create live demonstrations. You
Modern web development involves quite a few tasks, running servers, optimizing images and processing source code. Now these are the kinds of manual tasks that you can automate with: gulp grunt make or other build tools. The world of build tools is constantly changing, but we chose gulp here for its relative longevity and its relative simplicity simply put gulp reads: a file called the gulp file to tell it what to do it then processes your source files, transforms them and writes the results To a build directory, this is a sample golf rjs file, it’s written in JavaScript with a couple of no js’ extensions for loading, other files, the require statements of the top load, the core gulp commands and the gulp interface to uglify.
These are known as gulp plugins and by the way, uglify is a program to compress and minify javascript. Now, gulp files are divided into a series of tasks. A task might run a server minify some code or even delete files. Each task should be one self-contained action. We define a task named uglify j/s and write some JavaScript to implement it. The gulp dots sauce task reads all the J’s files from source J s.
We then pass all those files into the uglify tool using the pipe command. Now the output of each command is ready to pipe into the next, so we use the gulp nest command to write the result into new files under dist J s. Snap formerly gulp is a cross-platform streaming task. Runner that lets developers automate many development tasks at a high level, gulp reads: files as streams and pipes the streams to different tasks.
These tasks are code based and use. Plugins the tasks modify the files building source files into production files to get an idea of what gulp can do check the list of gulp recipes on github gulp is an ode package and the plugins that it uses are also node packages. So you need to install node.Js first, this also installs the node package manager, and you should also enable gulp from the command-line and to do this install the gulp CLI package.
You can then go into your project or create a new one and have NPM install the gulp plugins. You need into your project right, your gulp file, j/s, and you can begin using gulp from the command-line here’s an example of creating a project and installing gulp plugins. The first line creates a new NPM project. This generates a package JSON file that lists your project’s plugins. The following commands install various example plugins, including gulp itself: the save dev flag updates the package JSON file with the corresponding plug-in the plugins are installed in a node modules directory with this method, you can easily reinstall all plugins and their dependencies later by using the package.
Json file, rather than reinstalling each plug-in individually, now note that plugins, a B and C a imaginary we’re just using those names to show how plugins work once the plugins are installed. They need to be loaded into the gulp file using require now you’re ready to define tasks. This task is named task ABC. It takes file from the some sources, files path and pipes and through functions from each of the plugins which modify the files.
The processed files are passed to gulp tests, which writes the files to some destination path. The task we just defined can be run from the command line by typing gulp space and the task name in this case. It’s gulp space task, ABC here’s a set of links for learning more about gulp ins. We’ve also built a code lab that takes you through common tasks, follow the link to get to the lab. Now don’t worry if you’ve missed any details, just look at the gulp documentation and our to find out more.
We supply gulp files with our code labs, so you’ll be all set for now. Let’s get back to writing PWA s and i’ll see you soon.
You’Ll learn what a service worker is and what it can do for your apps. A service worker is a client-side programmable proxy between your web app and the outside world. It gives you fine control over network requests. For example, you can control the caching behavior of requests for your site HTML and treat them differently than requests for your site’s images.
Service workers also enable you to handle push messaging now. Service workers are a type of web worker, an object that execute the script separately from the main browser thread. Service workers run independent of the application they are associated with and can receive messages when not active either, because your application is in the background or not open or the browser is closed. The primary uses for a service workers are to act as a caching agent to handle network requests and to store content for offline use and, secondly, to handle push messaging.
The service worker becomes idle when not in use and restarts when it’s next needed. Now, if there is information that you need to persist and reuse a course restarts, then service workers can work with indexdb databases. Service workers are promised based now we cover this more in other materials, but at a high level a promise is an object. These are the kind of placeholder for the eventual results of a deferred and possibly asynchronous computation service workers also depend on to api’s to work effectively fetch a standard way to retrieve content from the network and cache a persistent content storage for application data.
This cache is persistent and independent from the browser, cache or network status now because of the power of a service worker and to prevent man-in-the-middle attacks where third parties track the content of your users. Communication with the server service workers are only available on secure origins served through TLS using the HTTP protocol will test service workers using local host, which is exempt from this policy.
By the way, if you’re hosting code on github, you can use github pages to serve content. Their provision with SSL by default services, like let’s encrypt, allow you to procure SSL certificates for free to install on your server Service Worker, enabled applications to control network requests, cache those requests to improve performance and to provide offline access to cached content. But this is just the tip of the iceberg.
We will explore some things you can do with service workers and related api’s caching. Assets for your application will make the content load faster under a variety of Network conditions. Two specific types of caching behavior suitable for use are available through service workers. The first type of caching is the precache assets during installation. If you have assets, HTML, CSS, JavaScript images so on, and these are shared across your application.
You can cache them when you first install the serviceworker when your web app is first opened. This technique is at the core of application. Shell architecture now note that using this technique does not preclude regular dynamic caching, you can combine the pre cache with dynamic caching. The second type of caching is to provide a fallback for offline access using the fetch API inside a serviceworker.
We can fetch request and then modify the response with content other than the object requested use this technique to provide alternative resources in case the requested resources are not available in cache, and the network is unreachable. Service workers can also act as a base for advanced features. Service workers are designed to work as the starting point for features that make web applications work like native apps, and some of these features are blog messaging API, which allows web workers and service workers to communicate with each other and with the host application examples of this Api include new content notifications and updates that require user interaction.
The notifications API is a way to integrate push notifications from your application to the operating system native notification system. The push API enables push services to send push messages to an application service can send messages at any time, even when the application or the browser is not running. Push messages are delivered to a service worker which can use the information in the message to update local state or display a notification to the user background.
Sync lets you defer actions until the user has stable connectivity, and this is really useful for ensuring that whatever the user wants to send is actually sent. This API also allows servers to push periodic updates to the app, so the app can update when its next on line. Every service worker goes through three steps in its lifecycle, registration, installation and activation to install the service worker.
You need to register it in your main JavaScript code. Registration tells the browser where your service worker is where it’s located and to start installing it. In the background, for example, you could include a script tag in your site’s index.Html file or whatever file you use. Is your applications entry point with code similar to the ones shown here? This code starts by checking for browser support by attempting to find Service Worker as a property in the navigator object.
The service worker is then registered with navigator dot Service Worker dot register, which returns a promise that resolves when the service worker has been successfully registered. The scope of the service worker is then logged with registration, dot scope. You can attempt to register a service worker every time, the page loads and the browser will only complete the registration. If the service worker is new or has been updated, the scope of the Service Worker determines from which path the service worker will intercept requests.
The default scope is the path to the Service Worker file and extends to all directories below it. So if the Service Worker script, for example, Service Worker dot gif, is located in the root directory, the Service Worker will control requests from all files at best domain. You can also set an arbitrary scope by passing in an additional parameter when registering in this example. We’Re setting the scope of the Service Worker to slash app, which means the service worker will control requests from pages like slap slap, slash, lower and slash out, slash, lower slash low directories like that, but not from pages like slash, app or slash, which are higher a Service worker cannot have a scope above its own path.
This is in your service worker file, service worker, dot, j s now thinking about installation. Once the browser registers a service worker, the install event can occur. This event will trigger if the browser considers the service worker to be new either, because this is the first service worker encountered for this page or because there is a bite difference between the current service worker and the previously installed one.
We can add an install event handler to perform actions during the install event. The install event is a good time to do stuff, like caching, the apps your static assets using the cache API. If this is the first encounter with the service worker, for this page, the service worker will install and if successful, transition to the activation stage upon success once activated, the service worker will control all pages that load within its scope and intercept corresponding network requests.
However, the pages in your app that are open will not be under the serviceworkers scope, since the serviceworker was not loaded when the page is opened to put currently open pages under serviceworker control, you must reload the page or pages. Until then, requests from this page will bypass the serviceworker and operate just like they normally would service workers maintain control as long as there are pages open that are dependent on that specific version.
This ensures that only one version of the serviceworker is running at any given time. If a new serviceworker is installed on a page with an existing serviceworker, the new serviceworker will not take over until the existing serviceworker is removed. Old service workers will become redundant and be deleted once all pages. Using it are closed. This will activate the new serviceworker and allow it to take over refreshing.
The page is not sufficient to transfer control to a new serviceworker, because there won’t be a time when the old serviceworker is not in use. The activation event is a good time to clean up stale data from existing caches. The application note that activation of a new serviceworker can be forced programmatically, with self dot skips waiting service workers are event-driven installation and activation events, fire off corresponding events to which the serviceworker can respond.
The install event is when you should prepare your serviceworker for use. For example, by creating a cache and adding assets to it, the activate event is a good time to clean up old caches and anything else associated with a previous version of your serviceworker. The serviceworker can receive information from other scripts through message. Events. There are also functional events, such as fetch push and think that the serviceworker can respond to to examine service workers navigate to the serviceworker section in your browsers, developer tools, different browsers, put the tools in different places, check debugging service workers in browsers for instructions for Chrome, Firefox and opera, a fetch event is fired every time a resource is requested.
In this example, we listen to the fetch event and instead of going to the network, returned the requested resource from the cache assuming it is. Their service workers can use background sync here. We start by registering the service worker and once the service worker is ready, we register a sync event with the tag foo. The service worker can listen to sync events. This example listens for the sync event, tagged foo in the previous slide.
Do something should return a promise indicating the success or failure of whatever it’s trying to do if it fulfills the sync is complete. If it fails, another sync will be scheduled to retry retry syncs also wait for connectivity and employ an exponential back-off. The service worker can listen for push events, push events are initiated by your back-end servers through a browsers push service. This example shows a notification when the push event is received.
The options object is used to customize the notification. The notification could contain the data that was pushed from the service service workers can be tested and debug in the supporting browsers, developer tools. Screenshot here shows the chrome dev tools application panel. There are lots of great resources to help you get started and find out more access them from the materials that accompany this article.
In the lab materials that accompany this article, you can practice working with service workers and learn more about intercepting Network requests.
Website management packages are important for any business these days. Check out the video from Allshouse Designs to see what can be done for your company and yes, for how much.
My guest is jeff posnick, he’s on Google’s developer relations team and today we’re talking about service workers and how they’re elevating the capabilities of progressive web apps. Let’S get started all right, so Jeff, thanks for being here in the context of web technologies. What does it mean for a worker and what does it actually do so? The whole idea of a worker has been around for a while.
Traditionally there were web workers and it’s basically serves as almost like a background thread for the web, so a worker can execute JavaScript code, that’s kind of independent from the context of your actual web page and it’s a great way to kind of offload processing or I Do tasks that might take a certain amount of time without slowing down the main thread for your web page and yeah, that that’s kind of should been the traditional model for workers on the web.
So now what does it mean for a Service Worker? What does that? Actually do the service workers builds kind of on that concept and adds some superpowers really things that you were not able to do before so a service worker is similar to worker and that it’s, you know, running independent from your actual web page and it doesn’t have Access to things like the Dom you know or the global scope of your web page, but unlike workers, it could respond to specific events and some of those events relate to network traffic.
So one of the really cool things and most common use cases for a Service Worker is to respond to outgoing Network requests that your webpage might be making, and you can kind of sit in between your webpage and the network and almost serve as a proxy that You control and you could write code to take advantage of things like the cache, storage, API and say hey. You know, I know how to respond to this particular request without having to go to the network.
I could just use this cache response and thereby saving you know the uncertainty and unreliability that comes with coming against the network. It also enables capabilities like push notifications, etc. Yeah so there’s a whole bunch of kind of event based listeners that you can set up in the Service Worker, including responding to portion of vacations. That may come from a notification server and you know fetching requests and people other kind of interesting things are kinda slated for the future as well.
So what’s the status of its implementation and support? Yes, the service workers are well supported right now in modern browsers. So pretty much anything Chrome or chromium based, Firefox, Safari and edge at the moment, it’s great. They all have at least a basic level of support for service workers and some of the enabling technologies, like the cache storage API, so they’re they’re ready to use right now.
So web sites may experience Network reliability issues at any. Given time, would you recommend service workers for every website? Should they all be using one? Well, I mean it’s tempting to just throw a service worker up and see what happens. I would suggest to take a little bit more of a considerate approach before adding a Service Worker to your web app. Ideally, a service worker will kind of play the same role that your web server would play and maybe share the same logic for doing routing and templating that your web server would normally respond with.
And if you have a setup where, like your web server, for instance from a lot of single page apps, the web servers just can respond with some static HTML that could be used satisfy any sort of request. That’S pretty easy to map into a Service Worker behavior. We call that the app shell model or a service work role say: hey. You know, you’re navigating to XYZ URL. I could just respond with this HTML and it’ll always work.
So that’s a really good model for using a serviceworker. If you have a single page app we’re also seeing some success with partners or using models where their servers implemented in JavaScript, they have some routing logic and they have some templating logic. That’S on JavaScript, and that translates over really well to the serviceworker as well, where the serviceworker you just basically fill the role that the server would normally play.
I would say if you have a scenario where your back-end web server is doing a whole bunch of complex templating and remote API calls and language that is not JavaScript. It really might be hard to get your serviceworker to behave exactly the same way. So in those scenarios I mean you can add a serviceworker and we have some kind of provisions in place to not pay the price of having that serviceworker, intercepting all requests and then not doing anything and just going on against the network.
There are waves of saying, hey, you know we have a serviceworker, but we’re not going to be able to respond with HTML for navigation requests. In those scenarios it is still possible use the serviceworker for things like ok, show, custom offline page when you detect that a user’s network connection is down or implement a kind of interesting caching strategy, like still while revalidate for certain types of resources.
So it is still possible to add a serviceworker in those cases, but you won’t necessarily get the same performance and reliability benefits that you get when your serviceworker really respond to all navigations with HTML by essentially having a network proxy juggling requests and responses. Is there a latency cost of having a serviceworker yeah, so I mean you’re you’re running JavaScript code, that’s sitting in between your web app and then a work and that’s not for me.
Some of it depends upon whether the serviceworker is already running. One of the kind of neat features about a serviceworker is that just it’s particularly to preserve battery on mobile devices? It’S killed pretty aggressively. It doesn’t just keep running forever in the background. So sometimes you do have to startup the serviceworker again and there is a cost involved in that startup. There’S a really good talk from the chrome dev summit that just happened a couple of months ago that kind of goes into some metrics and real-world performance.
Timings of you know exactly how long it takes to startup a serviceworker, seeing tens to hundreds of milliseconds depending upon the actual device and things like the storage beautiful device. So you are going to be paying that cost. Potentially, when you’re using a serviceworker – and you know again – that’s really why it’s important to make sure that you have a strategy in place for responding to requests, hopefully by avoiding that work and just going against storage API.
Ideally, and if you’re doing that, then you should see the service worker give you an that positive in terms of performance, you know paying tens, maybe even hundreds of milliseconds is nothing compared to the multiple seconds. Simply didn’t see that you might expect from making a network request each time you navigate to a new URL right. What’S the saying the fastest request is the one that you never need to make indeed yeah.
So what are some anti patterns that you’ve seen the way that people have implemented service workers? There’S a lot of power involved in using a Service Worker? It is just JavaScript that you could write that will pretty much do whatever you want, so you can do all sorts of crazy things, some of which are kind of cool as proof of concepts, but not necessarily things you want to deploy to production in terms of The things that we’ve seen kind of as pain, points or things that are pretty easy to, unfortunately get wrong when implementing a Service Worker.
I think one of the things that it’s most common is caching requests and responses, as you go without having any sort of upper limit on the amount of data that you’re storing. So now you can imagine a website that maybe has a bunch of different articles. Each of those articles has images it’s pretty easy to write a serviceworker that just intercepts all those requests and takes the responses, save some in the cache, but those cached responses will never get cleaned up by default.
There’S not really any provision in the cache storage API for saying you know stop when you reach 50 or 100 entries, or something like that, so you could very easily just keep using up space on your users devices and potentially use up space for things that are Never going to be used again, you know if you have an article from a week ago and you’re caching, all the images and that article that’s kind of cool.
I guess if you’re going to be visit article immediately, but if it’s a page that users never going to go to again, then you’re, really just caching things for no reason. I would say that really one of the important things before you implement your serviceworker kind of have a strategy for each type of request and say: here’s my navigation requests that are being made for HTML; here’s how I’m going to respond to them here.
The image requests. I’M making you know, maybe it doesn’t make sense to cash them at all, or maybe certain it only cache certain images and not others. So thinking about that – and that really just means getting really comfortable with the kind of network info panel in the browser’s dev tools and just seeing the full list of requests are being made. You know. Sometimes your web app is making requests.
If you don’t even realize it’s happening and it’s coming from the third-party code and your service worker ends up seeing that too, so you want to make sure that you know what your service work is doing. You know what your web app is doing and just one other. I would know that a lot of times and kind of pain, point and things that could go wrong with me using a service work, but just has to do with controlling updates to resources.
So you know you are stepping in between. You know your web app and a web server you’re responding, potentially the cached resources, if you’re not sure that those cached resources are being updated. Every time you make changes to your actual website and you read – apply to your web server, it’s possible that your users will end up seeing stale content kind of indefinitely, and this is a trade-off like seeing stale content, but avoiding the network gives you performance benefits.
So that’s that’s good for a lot of scenarios, but you do need to have a provision in place for updating and making sure that you know. Maybe the user sees still content then the next time they visit the site. They get fresh content. So you know you could do that right. Unfortunately, you could get that part wrong and the users can end up the frustrating experience. So you maintain a tool called work box j/s.
What is that? What does it do sure so? Work box is open source and a set of libraries for dealing with service workers and kind of all aspects of building service workers. So we have some tools that integrated with build processes, including you know we have web pack plugin. We have a command line tool. We have a node module and that aspect of the tools, basically, is something you can drop in your current build process and kind of get a list of all of the assets that are being produced.
Every time you rebuild your site along with kind of some fingerprinting information like say you know, this is a particular version of your index. Dot HTML work backs will keep track of that for you and then it will efficiently cache all of those files that are being created by your build process for you and that just helps ensure that you don’t run into scenarios like I just described where you’ve rebuilt.
Your site – and you know you never get updates to your previously cached resources and we also have some tools as part of work box, that kind of harm or execute at runtime. That’S part of the serviceworker, so some libraries for doing common things like routing requests. We have there’s just kind of some canonical response strategies for dealing with caching, so things like still while we validate or going cache.
First, we have implementations of those strategies inside of work box, and then we have some kind of like value adds on top of what you get with the basic serviceworker spec in the cache stored specs. So we actually have an implementation of a cache expiration policy that you could apply to the caches that would otherwise just grow indefinitely, but using work box you could say, hey. You know it actually like to stop.
When I reach ten items and purge the least recently used items and just cache when that happens, and a few other kind of ran two modules, we see it as a bit of a kind of grab bag for all the things that somebody might want to do With a serviceworker and we kind of ship them as individual modules, you can choose the ones that you think would be useful for your particular use case. I don’t want to use something, that’s fine, you don’t have to incur the cost of you know downloading it or anything like that.
Do you foresee some of those caching and expiration policies making their way back into the cache storage API yeah. I mean it’s kind of interesting whenever you have something: that’s almost like a polyfill for some behavior on the web. You know whether that ends up being implemented back into the standards, and you know the the actual runtime could just fade away and just use the underlying standards.
And you know I’d like to see that. I think that where cost has been really great for kind of enabling folks to ship service workers in production and seeing the types of things that they actually need, when you’re shipping somebody in production and a lot of times when you could do that and get points. As a vision thing like yeah, you know it is actually important to have run time, cache expiration.
That could then be used. You know when going to different standards, groups and saying hey, we really do need to extend. You know, what’s supported natively in the platform, to take care of this really common use case. You know what that actually happens or not remains to be seen, but you know I think work box is positioned to help folks with kind of that initial, proving that these things are necessary stage kind of take it from there.
So, in terms of adoption, according to the HTTP archive, less than 1 % of websites tested actually include a serviceworker which is kind of a misleading number. For two reasons. The first is that it’s actually growing at a very fast rate and the websites that do include it are actually pretty popular websites. Can you give us some examples of those yeah? So I think you know the raw number of URLs unique URLs might be on the lower side, but I think in terms of traffic, you know sites as big as Google search have deployed a serviceworker for some types of clients.
You know partners that we’ve talked about using work box, in particular in the past and Gleevec Starbucks has a nice progressive web app, that’s implemented Pinterest as well, and there’s also some sites that you might have heard of like Facebook and Twitter that are using service workers. Not using work box but using them to kind of unlock things like you know, they’re progressive web app experience – or you know in some cases just showing notifications, which is important part of you know being on the web and having parity with native apps.
So you know, I think that the actual number of you know you visits to web pages is probably much higher than the 1 % number would indicate, and you know I mean there are challenges with adding a service worker into especially legacy sites. You know it does. Take that coordination that we talked about before tree, making sure that your service worker actually is behaving in a similar way that your web server would behave and yeah that doesn’t always fit into existing sites.
So a lot of times we’ve seen when working with partners in particular, is like you know: you’re planning a rewrite, re architecture of your site anyway, that’s a great time to add a service worker in and just kind of take care of that story as well. Are there any options for CMS users who may be using things like WordPress or Drupal? So there definitely are, and I think that you know first of all, I’d work for everybody back to another talk from the most recent chrome dev summit.
That really goes into some detail about the WordPress ecosystem in general, so they have a really cool solution, some folks from the dev rel team that Google have been working on it and I think it kind of works around one that that problem. I was saying where the architecture for your kind of back-end web server needs to match up with the serviceworker implementation I kind of just sending a baseline.
So it’s not an attempt to take any arbitrary, WordPress site that might be out there, which might be executing random PHP code depending upon you know what kind of themes and extensions and all the other stuff is going on. You really are not going to be able to successfully translate that into just a general-purpose serviceworker, but the approach that was subscribed and this talk. It seems to be building on top of a kind of a common baseline of using the amp plugin as a starting point.
So any site that has gone through the effort of kind of meeting all the requirements for using the amp plugin. So it means I don’t know the full set, but I think, like not running external scripts, not doing anything too crazy with other plugins. That’S inserting random HTML on the page building. On top of that, you can then have a serviceworker. That’S like okay. I actually do know how to handle this subset of activities that you know WordPress is doing when it’s using the unplug in and it can automatically generate that serviceworker for you.
So again, it’s part of a migration story. I think it’s not going to just drop into any existing legacy WordPress site, but it does give a nice path forward for folks who are planning on rewriting anyway are planning on making some changes anyway, and plugging into the CMS ecosystem is great way to increase adoption By tens of percents on what yeah absolutely so, what kinds of resources would you recommend for someone who’s just getting started with service workers? We have a lot of material available, some of which is more recent than others.
I would say that the things that I worked on most recently are the resiliency section of web dev. So if you were to go there kind of have something I would walk you through the various steps of thinking about adding a service worker to your website or just really thinking about making your website more resilient in general. So it’ll talk about you know identifying your network traffic it’ll talk about using the browser’s HTTP cache effectively, which is kind of your first line of defense, and then it all kind of go into how you could add work box to an existing site and the various Steps involved there, so if you want kind of a guided path, I would say that’s one option we’ll biased.
For that. I would say that if you want to just learn more about service workers in general and material written by my colleague, Jake Archibald, it’s probably the best that for folks who really want to deep dive on things, he was somebody who worked on the actual serviceworker specification And you know he knows more than anybody else about these things, so he was a really great article talking about the serviceworker lifecycle, just all the different events we have fired, and you know how you have to handle those events differently and implications that they have for You know the state of your caches and updates, and things like that so diving into that would be kind of my recommended starting point, and he has another article that talks about kind of a cookbook almost for recipes for caching, so implementations of the stove are valid.
A pattern cache first pattern: if you wanted to implement it yourself, instead of using work box, he kind of walks through the process. There is that the offline cookbook, yes, the offline cookbook, and if you want something, that’s really offline, there’s some actual physical books that that are pretty cool, related to service workers and progressive web apps in general. There’S a new book written by Jason, Grigsby, eight in particular, that I would recommend and just kind of talks a little bit about, I’m necessarily some of the technical aspects of service workers, but more about why you should think about adding a service worker to your site And why you might want to build progressive web app in general and that’s a really cool book, that kind of takes it from a slightly different angle, but gives some good perspective great Jeff.
Thank you again for being here. Absolutely you can find links to everything we talked about in the description below thanks a lot and we’ll see you next time.
Website management packages are important for any business these days. Check out the video from Allshouse Designs to see what can be done for your company and yes, for how much.